Several years ago, I found myself confronted with the decision of whether to open source or not the software of a company I co-founded. While I could find considerable literature on the strategic benefits of open-source freeware as an enabler modern version of the razor and blade strategy (giveaway the client or development tool or razor, sell the server or the runtime or the blades), our software was not lending itself very well to such a separation.
My question was rather: if we have to choose between open sourcing blades and razors or nothing, what model would maximize our revenues, given our target market?
By elaborating on the simple notion of “why giveaway something you can charge for”, I developed the chart below to help me discuss the decision with my colleagues. The idea is to not view open source as an all or nothing strategy, but rather as a marketing technique to segment your market and maximize revenue, except that in the open source case, the revenue is mostly intangible.
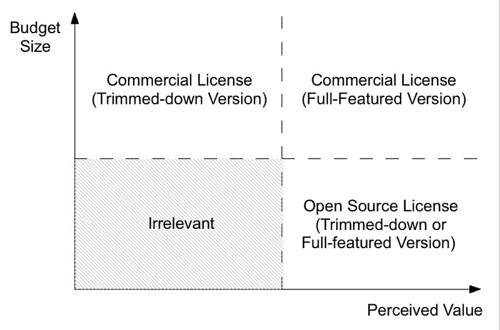
According to traditional marketing segmentation strategies, customers with large budgets and who have a high perceived value of our software should be charged for it fully and get all the features and rights; and customers with small budgets and who have a lower perceived value of our software should be charged less for a slimmed-down version of the software.
What’s new here is the category of users who don’t have large budgets themselves (the boss of their boss may have as it is the case of developers) but who see a lot of value in the software. These guys may not be able to sign a check, but they are able to bring more eyeballs to fix bugs, post feature requirements that are common to all users whether they have a checkbook or not, or simply spread the word about your software at the fraction of the cost and in a much better way than any PR firm. That’s not direct revenue, but certainly contribute to higher margins by reducing the costs of goods sold.
In most cases, the distribution of target customers (as it was the case for us) is such that a single model (commercial or open source) will dominate:
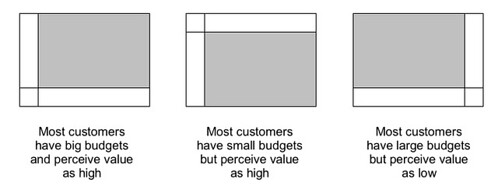
But if the distribution of customer types is such that a single model does not dominate, this model can actually be implemented using dual licensing, where one category of customers is segmented from another and charged differently, by offering both a commercial license and an open-source, usually GPL-like license. What’s even better is that customers are let to choose which category they belong to (actually their lawyers tell them).
